Klarna, the highest-valued private fintech in Europe, is on a mission to make shopping simple, safe and smooth, for both consumers and retailers, through its suite of payment products and services. From its inception in 2005, Klarna has not compromised on providing a seamless consumer experience — even when it comes to consumers in collection.
With a high standard for customer experience and in an effort to integrate collections seamlessly with their product, Klarna initially opted to keep collections in-house. For five years the company had great results with in-house collections, but as Klarna expanded to new markets and added new products, scaling in-house collections while maintaining a best-in-class customer experience strained the company’s resources and became less feasible.
This led Klarna to begin considering a third-party collection partner. By this time, the collections industry had evolved. New players like TrueAccord were building digital-first collection solutions that vastly improved the customer experience via personalized outreach, flexible payment plans, and a self-optimizing, machine learning-driven performance engine.
It’s easy to underestimate the expertise involved in building an effective, compliant digital debt collection engine, and partnering with the right collection solutions provider would free up valuable internal resources. Klarna’s priority was to focus on their core business and engage an expert partner who would be able to build a world-class collection operation for them — one that would only enhance their consumer experience while not sacrificing brand image.
“We look at collections partners the same way we look at hiring team members: we only want to work with the absolute best. We wanted to partner with a company that truly takes care of consumers,” said Jan Hansson, VP Debt Collection, Klarna.
Other key considerations to moving away from in-house collection included, data science expertise, engineering talent, compliance resourcing and industry knowledge. After doing their due diligence, Klarna decided to partner with TrueAccord as a collection solution provider. TrueAccord stood out from competitors in two important ways: customer centricity and digital and multichannel capabilities.
By partnering with TrueAccord, Klarna was able to increase liquidation rates and achieve better holistic results, with retention rate a key indicator. Moving to a partnership with TrueAccord from in-house collection also allowed Klarna to free up valuable internal resources and refocus on their key business functions. Klarna is now expanding their engagement with TrueAccord to include more accounts and looks forward to growing the partnership even more in the future.
“We are so proud to work with TrueAccord,” said Sebastian Siemiatkowski, co-founder and CEO, Klarna. “Putting technology to use for the people instead of against the people is the next generation of tech.
Banks are accelerating their adoption of new digital debt collection tools in anticipation of a “tidal wave of consumer debt issues” when government stimulus programs end and financial institutions stop offering forbearance and loan deferral options.
That’s the premise of a new article in American Banker highlighting a variety of technology-powered strategies banks are using to make debt resolution more automated, conversational, and empathetic. These approaches range from the convenient (more flexible self-service payment options) to the high-tech (robotic process automation).
The American Banker article highlights promising signs of progress, particularly for industry players that have not always been known for digital adoption. KeyBank, for example, is in the process of rolling out a self-service digital payment portal designed to offer banking customers privacy and flexibility in resolving payments. And Alabama-based Regions is implementing digital messaging and intelligent interactive voice response (IVR).
At the same time, the article shines a light on the massive challenges facing any financial institution looking to implement intelligent digital debt collection at scale. Here are three common hurdles on the path to digital debt collection maturity – and why they matter:
Challenge #1: “One-size-fits-all” approaches
The challenge: In its overview of Regions, the article makes reference to a single conciliatory messaging tone used in all outreach to delinquent customers.
Why it matters: Consumers differ vastly in their preferences and responsiveness to digital touchpoints. For example, one consumer might respond to a friendly message delivered by SMS, while another might respond best to a straightforward message delivered by email. As a result, a one-size fits all approach falls short of realizing the potential – in both performance uplift and customer experience – of true one-to-one personalization.
The TrueAccord approach:HeartBeat, TrueAccord’s patented machine learning platform, mines through tens of millions of data points to optimize digital outreach on the individual level within a programmed set of compliance rules – and continues learning the more data it analyzes.
Challenge #2: Narrow, channel-specific use of machine learning
The challenge: Another challenge that banks face in scaling their use of intelligence – including artificial intelligence (AI) – is the limited deployment of algorithms and optimization within a single kind of channel, such as in a call center environment. The article profiles a collections and business process outsourcing company, for example, that developed an AI-based virtual assistant that can handle most inbound phone calls.
Why it matters: Machine learning and artificial intelligence (AI) are powerful tools for restoring intimacy and relevance to customer relationships at scale. At their most useful, these tools should be deployed to personalize the customer’s full experience with a bank – not just the limited interaction on one channel.
TrueAccord’s Approach: HeartBeat captures a continuous data feedback loop and optimizes for each customer touchpoint across a variety of digital channels, ensuring that each customer is being reached on the channel that is most relevant for her.
Challenge #3: Building a truly comprehensive and flexible self-serve portal
The challenge: Constructing a digital portal that drives consumer adoption and usage takes major work. To truly match the convenience of online banking, digital tools must also allow consumers to adjust the length and installment amount on a payment plan, defer a payment, dispute all or a portion of their debt, apply for a hardship pause on their debt, and much more.
Why it matters: Research suggests that customers want to be able to self-serve. But doing so requires the full, flexible range of interaction options that would be available to them through traditional analog channels.
TrueAccord’s Approach: Through a robust and flexible digital platform, TrueAccord offers a best-in-class self-serve experience: over 95% of users resolve their accounts without ever directly communicating with an agent.
Ultimately, digital debt collection technologies offer banks the ability to build lasting relationships with their customers. As Kimberly Snipes, consumer chief information officer at KeyBank puts it in the American Banker article: “We want our customers to say, I hate that I had that situation, but I felt like my bank was working with me, not against me.”
Being aware of the challenges on the path to digital debt collection – and having a plan in place to address them proactively – can help financial institutions ensure that they’re set up for long-term success.
About TrueAccord
TrueAccord is reinventing the relationship between creditors and lenders with a machine learning-driven, digital approach to debt collection. Our technology personalizes outreach to each customer across digital channels, continuously optimizing for performance while delivering a customer experience that builds long-term brand loyalty. Schedule a demo today to learn more.
New products in debt collection seek to solve decades-old problems with traditional collection strategies. Products and services seek to improve the collections process and aim to improve contact rates, liquidation rates, brand perception, and ease of access.
When you combine agile product development with its application in collections, you’ll see new solutions to old problems. I recently spoke with Parker Lyons, TrueAccord’s Product Director, about his personal product philosophy, how he and his team are approaching product development, and the challenges faced by new product offerings in the space.
Parker Lyons, Product Director
Hi Parker! Thanks for joining me. I wanted to kick us off with an introduction. You’re fairly new to the collections industry. Can you walk me through what brought you to product development in debt collection?
Sure! When I finished college I started out in advertising for consumer packaged goods. I was living in Colorado at the time, so I was working on some ads for Coors Light and Polaris snowmobiles. I spent a few more years in advertising, but I ended up taking an interest in energy and renewables. I saw companies in the space with really impactful missions and the growth potential, so I went to school to get my Master’s [Degree] in Environmental Studies.
I ended up making my way out to California and started in solar. I met some people at Spruce Finance who are now working at TrueAccord, and had the chance to see the work TrueAccord is doing. I always had a very “Tony Soprano” view of debt collectors, but TrueAccord is something different. It’s a different type of mission, and we’re really helping people get back on their feet.
We’re happy to have you! How do you translate your product experience over from such a different industry?
Most recently I was with a company called BlueWave Solar that was a community solar business. Our product allowed consumers to subscribe to a percentage of a solar farm and apply the savings generated from that farm to their utility bill.
So we really were a servicing company. We had clients who were big banks and energy companies whose assets might differ from debt collectors managing portfolios, but the goal was the same: they wanted to keep accounts and cash flow moving.
And as you’ve started to consider meeting that goal for clients in debt collection, what are some things you’ve learned about the industry? Do you see consistent issues that you think need to be addressed?
Traditional debt collection platforms are using reliable systems. Call-and-collect methods have worked for a long time, but performance is waning and people aren’t picking up the phone anymore. A lot of the appeal though is that it’s a relatively simple model to get moving. You hire agents, you train them, and they start calling.
On the other side of that, we see some resistance to new technology, and I think that people are worried about it being too complex. So that falls on us. We have to meet clients where they are and focus on making integration easy. We have to maintain simplicity even though machine learning and digital tools can be very complex.
How do you go about making your product more easily digestible then? Where do you start when you’re trying to solve that problem?
It starts with knowing your user. Who are they? What’s their problem? You have to have a deep understanding of what makes them tick and their pain points because you then have to ask yourself “How do we solve that problem for them in a way that no one else can, or cheaper than someone else can?” In product management, we say that you’re responsible for creating a product that is valuable, usable, feasible, and viable. With those things in mind, you can turn your potential client’s issues into your value proposition and the capabilities of your company.
In product management, we say that you’re responsible for creating a product that is valuable, usable, feasible, and viable. With those things in mind, you can turn your potential client’s issues into your value proposition and the capabilities of your company.
As an example, we’re expanding with TrueAccord Retain, our product for first-party pre-charge-off solutions. We’ve scaled our capabilities with artificial intelligence and machine learning in late-stage collections, and early-stage is a natural extension of our growth and service value. In the age of COVID though, we’re seeing an increasing need for early-stage.
The major pain point we’ve seen is that it’s expensive to spin up and scale massive call centers quickly. We have a proven tech stack that can address the need to start quickly. Now it’s a matter of evaluating and understanding the unique challenges of collecting early-stage debts.
Are there projects outside of Retain that we’re currently working on that you’re allowed to share?
Our team is constantly asking “How do we bake all of our learnings into best practices?” One of our biggest projects right now is improving our own internal efficiencies. Everything that we’ve built so far has worked, but we need to—with higher account volume and higher growth rates—automate more of our own processes and move away from manual practices.
Another important piece of that is ensuring that processes are thoroughly documented. These growing pains are expected when an organization is growing quickly, and the more we grow, the more diverse our client base will get. We have to build on a foundation now that can accommodate that diversity consistently.
I’m also reflecting on what we know about our current users. We have to figure out the changes we hope to deliver for existing and future clients. Building a clear roadmap for that is huge which is why we’re working so closely on improving our internal organization. Improving our internal planning directly improves our product offering and client performance.
That’s really exciting to hear. I know how much the startup world prides itself on its ability to pivot quickly, but creating a more defined system makes that system scalable. We’re all incredibly excited to see what comes next!
Compliance regulations in the debt collection industry are built to protect consumers in debt from potentially predatory practices and ensure an equitable collections experience. For debt collection agencies, this often requires building out entire departments dedicated to keeping the agency in line with ever-changing debt collection laws and regulations. These teams are committed to reducing risk wherever possible.
One risk that is built into traditional debt collection practices is the potential for human error in a contact center environment. Digital debt collection platforms, however, offer code-driven compliance solutions that range from supporting existing agents to operating largely without the need for agent intervention.
Digital compliance solutions
Agent support
Operations managers throughout the collections industry cite high turnover rates in contact centers as a major challenge. While the exact number changes drastically depending on who you ask, contact centers may see annual agent turnover rates as high as 100%, but properly training contact center agents takes time (at TrueAccord our training process spans a full six weeks). High turnover in a space that requires thorough training means that newer agents may make mistakes when navigating important and complex regulations.
Some of this concern can be alleviated through the introduction of a curated content management system that provides prompts. These systems can be built with pre-written responses that adhere to compliance guidelines that improve agent compliance performance. While this may help to reduce the risk, the consumer experience is less than ideal.
Code-driven digital-first debt collection
Digital-first debt collection agencies and other debt collection software tools provide systems that allow for close control over what actions are taken and what messages are sent to consumers. These messages are carefully crafted by a dedicated content team, reviewed by a team of legal and compliance experts, and are easily accessible for auditing purposes. They are also then managed by the digital system once they are implemented.
Most importantly, these messages are then integrated into a digital, consumer-driven payment experience. More advanced systems use artificial intelligence and machine learning to customize a unique customer experience that is optimized for engagement and liquidation.
Compliant content creation
Pre-approved consumer-facing content
Building a digital debt collection system starts with creating compliant and adaptable content. Every email, text message, and landing page in a digital ecosystem is created by a team of dedicated content writers who draft and experiment with different approaches to encourage customer engagement. The guidelines used to draft these messages are shaped by collections laws, policies, and regulations.
Teams can also draft content that meets the needs of individual clients with specific brand considerations. Once the content is drafted, it is processed and reviewed by a team of compliance experts prior to being added to a content repository that the digital system can draw from.
Scalable compliance review process
The next step is to have a team of legal and compliance experts from within the debt collection agency review the content to ensure its adherence to the same regulations. Based on the client’s preferred level of involvement and resources, such a review process may also include a compliance team within the client’s organization. This process lays the foundation for compliant communication down the line.
Easily audited communication history
The content auditing process comes further down the line, but it is important to build that foundation early for the same reason stated above. Traditional call-and-collect debt collection agencies may record voice calls and even provide automated transcriptions of these calls. Unfortunately, these processes are not perfect because auditing activities can only review sample cases. Digital systems are able to accommodate a full audit-specific interface.
At TrueAccord, 96% of consumers resolve their accounts without communicating with an agent, so the vast majority of communications that exist are entirely automated and recorded. Compliance staff can easily search for individual accounts to review and evaluate all collections activity across multiple channels. Digital systems overall offer improved data retention and tracking to provide a clear picture of performance.
Because the system saves this data, it’s easy to investigate how it responded to a particular message, as well as why it made a specific decision. When these communications are controlled by code, decisions are easy to trace and replicate.
How do these steps lay the foundation for a scalable digital compliance system?
Once content is in place, and there is an established process for reviewing it, digital debt collection platforms can connect to consumers. At TrueAccord, our machine learning engine, Heartbeat, is able to draw from our content library and improve communications with a consumer over time. Digital systems reach out to consumers when and how they prefer and these communication decisions are driven by data, not by individual agent decisions or potential biases.
Digital systems reach out to consumers when and how they prefer and these communication decisions are driven by data, not by individual agent decisions or potential biases.
Digital debt collection systems rooted in machine learning are dynamic. The content they choose to use for an individual consumer is determined not only by historical data but how a consumer responded (or did not respond) to previous communications. Every single message in the system is vetted to meet compliance standards, and the review process is always ongoing to maintain those same standards.
At any point in the customer lifecycle, a consumer can opt-out of communications by replying to a text message or by clicking a link in an email that lets them easily unsubscribe from future communications using that channel. Each email and payment page also provides a link for consumers to request debt verification via a few simple online steps.
Coded compliance continues to scale
As the system scales and communicates with more consumers in this way, it’s able to continually enforce compliance without needing to be retrained because it is built to be compliant from the ground up. Built-in compliance checkers can prevent the use of contact methods that the consumer has unsubscribed from or ensure they do not receive a payment offer that the creditor has not approved.
Any compliance updates—such as new rules from the Consumer Financial Protection Bureau’s proposed rules—can be implemented securely and quickly at a company-wide scale rather than retraining on an agent by agent basis.
An improved, more secure consumer experience
Collections regulations and laws are largely driven by a need to protect consumers from bad actors in the industry. Digital debt collection empowers consumers to manage their accounts at their own pace and communicate using their preferred communication channels.
By evaluating content before it is ever sent and programming a platform that delivers unambiguous content you can reduce confusion and improve the user experience. Clear, compliant messaging enables consumers to resolve their accounts through self-service without added support. This leads to a dramatic reduction in consumer complaints, and in TrueAccord’s case, many positive online reviews.
A code-driven future for debt collection
Code-driven compliance offers predictable, pre-approved, and consistent collections methods. Coupling digital platforms with machine learning creates a system that improves over time and optimizes for a better user experience, guided by consumer preferences and shaped by compliance guidelines. This minimizes the need for agents to manage an account from start to finish and instead allows them to focus on more complex customer cases.
New technology is often seen as a risky investment, but digital debt collection systems offer more compliance security and more transparency—for consumers and creditors—than traditional debt collection agencies. Digital debt collection solutions not only evolve to meet consumer needs, but they can also continually adapt to changing regulations and quickly meet compliance requirements.
Do you want to see the power of a code-driven compliance platform in action? Reach out to our team today to see what this looks like at TrueAccord.
The age of digital communication has led to a dramatic shift in the way companies do business and in the way that people communicate generally. The collections industry is not exempt from this change. On April 22, TrueAccord’s CEO, Ohad Samet, spoke on how TrueAccord is pioneering a radical transformation for consumers and collectors alike, especially in the wake of the COVID-19 pandemic. This is a summary of the webinar.
Attempting to reach consumers in debt is becoming increasingly challenging. Reaching these same consumers during a rapidly evolving recession, when tens of millions of people in the US are filing for unemployment, is only making it more difficult. Beyond this, social distancing practices are limiting the ability of traditional call-and-collect based agencies.
There has been some progress made on improving work-from-home opportunities in collections, but 78% of TrueAccord’s clients are experiencing severe disruption of their 1st- and 3rd-party call center operations. This includes some collections partners shutting down entirely.
High agent turnover rates are a common issue for collections agencies due to the difficult nature of the work. Agencies typically expect turnover rates of more than 70%, and these numbers are climbing in the midst of the pandemic. All of these factors have largely left the collections industry in a holding pattern as we wait and see what changes may come, but what else can we do today to make change?
Finding the solution today
TrueAccord is focused on building sustainable, consumer experience-focused collections systems and tools. Our machine learning algorithm, Heartbeat, is a patented, scalable, tool that personalizes the collections experience with empathy-driven content for consumers. The multi-armed bandit algorithm learns from customer interaction and optimizes based on these behaviors.
Multi-armed bandit algorithms go beyond traditional decision trees or A/B testing. They optimize and learn as they grow!
What’s the difference between machine learning optimization and demographic segmentation?
Demographic segmentation is dividing a group of individuals based on demographic information such as age, gender, race, marital status, etc. when deploying a process or function. Machine learning optimization is teaching a computer model to evaluate the choices individuals make to improve a process or function. For example, in the credit and collections space, debt collectors typically approach customers during tax season to discuss using any tax refund to pay existing debts.
Our Heartbeat system learned that consumers do not like these suggestions—consumers who received content without the phrase “tax refund” paid their debt during tax season (likely with their tax refund) more than those consumers who received content with the words “tax refund.”
Samet explained, millions of consumers have completed payments and established payment plans using TrueAccord’s platform (through Heartbeat). The options employed by Heartbeat are based on its historical data learned through continued experimentation without access to an individual’s demographic information. Based on the millions of users that came before them, we can depend on Heartbeat to function as a complete virtual agent with built-in years of experience.
Customizable communication offers a personalized experience
While email is TrueAccord’s primary communication channel, Heartbeat is a multi-channel solution that includes but is not limited to, SMS (with consent), push notifications (with an opt-in), and a self-serve interactive platform. Other digital services segment channels to test with different audiences, or may specialize in one, requiring creditors to work with separate vendors. TrueAccord uses a multi-channel approach to reach consumers how they prefer.
In fact, more than 95% of users on our platform resolve their accounts without ever communicating directly with an agent. 80% of the consumers that do reach out to our team are able to resolve their accounts via email. Our dedicated team of agents is available to speak on the phone, but our digital tools allow each agent to service more than 80,000 accounts (and that number continues to grow). Some agencies are gradually scaling digital strategies, they still account for less than 30% of their overall operations.
In fact, more than 95% of users on our platform resolve their accounts without ever communicating directly with an agent.
While Heartbeat operates as the frontline of our digital strategy, TrueAccord’s phone number is always readily available. We firmly believe in using only one phone number, (866) 611-2731. This creates brand familiarity, drives engagement, and is consumer friendly. 97% of consumers ignore calls from unknown numbers because many companies buy phone numbers in all area codes. Their goal is to appear as if they are calling from the same area code as the consumer.
TrueAccord does not want to trick the consumer into answering an unknown call. We want to make it easy for consumers to search for our number online, do their own research about TrueAccord, and respond on their time. When consumers do reach out to our team, TrueAccord agents are trained to focus on customer care and on helping consumers to build the right financial plan to meet their needs.
Combining this approach to customer care with our machine learning algorithms allow us to expand our offerings to include new tools like a detailed self-service portal for payment plan adjustments. Consumers can customize payment plans that work for them, and this has led to a spike in plan creation and higher successful plan completion rates.
TrueAccord doesn’t want to pressure consumers to make payment amounts they cannot afford and make deadlines they can’t meet. Instead, we enable the consumer to fully personalize the repayment experience into a plan that meets the consumer’s ability and time frame. “We sell the experience of being debt free.” Samet says.
A different approach to collections
Traditional call-and-collect agencies are built on foundations similar to telemarketing: high agent turnover rates result from low-base, high-commission pay rates. These collectors are incentivized to collect and meet call minimums and payment quotas that lead to a rapid rise in complaints toward the end of pay periods as deadlines loom.
Machine learning algorithms don’t have the same stresses. The bounds of payment plans are defined by clients in advance. Heartbeat leans on historical customer data, consumer engagement behavior, and chooses content to inform consumers about the stress free experience of repaying debt using customizable on-line repayment tools. If the customer has any questions, they can always check in with our team by phone or email!
Changing the industry
TrueAccord’s changes are continuing beyond our technology. Our leadership team works directly with the Consumer Financial Protection Bureau (CFPB) to understand evolving best practices and remain at the forefront of regulatory change. Members of our legal team also work with the Receivables Management Association (RMAi), the Consumer Relation Consortium, and Association of Credit and Collection Professionals ACA International boards to keep up with trends in collections.
These experiences all point in a similar direction: legislators want to see fewer phone calls, more reliance on technology, and more consumer choice in the collections space. Building compliance adherence into TrueAccord’s system drives brings these changes together in one place.
How does TrueAccord fit into existing collections strategies?
TrueAccord is able to service at any stage in the debt cycle (early, late, warehoused, etc.), across segments, with competitive results. Our platform is built to accommodate your team’s needs, and we recognize that not every collections agency works perfectly in every segment.
We can easily increase or decrease the use of specific channels and optimize in whichever segments you see fit. While larger placement volumes provide more data and by extension clearer automated decision making, we fit into your strategy at any stage.
Pre-charge off
The same tech that supports TrueAccord’s post-charge-off product also offers new advantages and easy onboarding within a few short weeks for early stage delinquencies. Heartbeat can supplement your existing call center strategy. We’re also equipped to provide different levels of service in different phases.
This can be a small change to your normal business practices: uploading a traditional “dialer file” to our system. We can email payment reminder content driving your customers to your existing teams, tools, and webpages, while maintaining your branding. This can also involve full outsourcing through the use of our online self-service individualized payment portal as well as use of digital channels to drive engagement.
The next steps
We continue to scale and develop new tools for consumers to self-identify their current financial needs and provide new ways to work with them to adjust payment plans. We know that demanding payments isn’t nearly as effective as empowering consumers, and finding the right middle ground helps all parties involved.
Getting started with TrueAccord is easy with inbound file receipt or APIs and standardized, out-of-the-box reporting. It can be as simple as a .CSV upload to our secure dashboard or as complex as a long-term integration period designed to align our systems, policies, and procedures to your own.
Ready to join the future of debt collection? Do you still have questions about how TrueAccord can help your team? Get in touch with us today!
Email is only one of many powerful digital channels at your disposal when it comes to connecting with consumers. Regardless of which of these channels you decide to use to reach those consumers, you also have to decide how to measure the effectiveness of your new digital tools.
We’ve discussed email deliverability and what it means to collections, but once you have the proper email infrastructure in place, your team’s focus should shift toward both measuring the impact of those email efforts and understanding what declining performance can mean to your collections process. Here are a few things to keep in mind so that you can minimize the impact of deliverability issues and optimize your contact rates.
Build a baseline
The first step in effectively correcting email deliverability problems is to start with a baseline that you can compare to. Measuring the impact of issues on your digital collections strategy requires your team to establish what “normal” looks like for your business. Some engagement-related metrics that matter most to email-based digital debt collection typically include:
Open rates
Click rates
Conversion rates
For email marketers, conversion rates signal when users take a desired action after engaging with marketing material. These actions often involve making a purchase or signing up for a product demo. In collections, conversion rates are measured by a combination of email engagement metrics and the more traditional liquidation rates. The desired action your collections team is looking for is a promise to pay or a completed payment.
With a baseline set for your digital performance, you can compare your average conversion rate to any fluctuations you see in your deliverability. Tracking this data over time then helps you to clearly measure how your deliverability rates impact collections and how specific deliverability issues (send volume, send time, content, etc.) impact your bottom line.
Identify and monitor engagement with deliverability
Email deliverability rates directly reflect whether or not you are reaching consumers’ inboxes, but your engagement shows you whether or not your consumers are taking action. Tracking deliverability in tandem with engagement metrics can provide insight into what changes need to be made to accommodate potentially shrinking inboxing rates. Here are two important correlations to keep an eye on.
Stable open rates and decreased deliverability
If you notice a decline in deliverability, but consistent open rates, there is a strong chance that your email list is out of date or a newly imported list contains incorrect contact information for your consumers. Consumers in your system that are listed correctly are continuing to engage at the same rate, but you have a higher number of bounces or failed sends.
Email validation is an important step in limiting the chances of a situation like this happening as this process confirms whether or not email addresses are legitimate. Large lists may contain small typos or transpositions that would turn an otherwise valid email address into a useless string of characters.
Decreased open rates and decreased deliverability
In the event that there is a decrease in both open rates and deliverability, it is likely that your send domains (the part of an email address after the @ sign) are being blocked or blacklisted. Fewer recipients are actually receiving your emails and even fewer are opening them.
There are a number of steps an organization can take to prevent this downtrend including using multiple domains and carefully scaling an email strategy before attempting to reach thousands of consumers. Attempting to remedy these issues after they have happened may prove to be too late.
Recognize the scope of an issue
Sending collections emails at scale can mean trying to reach thousands of consumers per day. It’s difficult to imagine a process of that scale without some sent emails not bouncing or simply being ignored.
As we mentioned earlier, a massive downturn in deliverability can lead to email domains being blacklisted which means those messages will be relegated to spam folders across ISPs (internet service providers). TrueAccord’s in-house Head of Email Operations, Raja Datta, has some extra advice (which was also contributed to a segment for Kickbox) for those looking to prevent these issues from causing further damage.
Attempting to recover your domain authority (proving to ISPs like Google or Yahoo that you aren’t a spammer) at that stage is remarkably difficult, but if you recognize a downtrend in click-rates, you can make relatively minor changes to the content of an email (phrasing on a call to action, different subject lines, etc.) to improve engagement.
The scale of your deliverability issue will dictate how urgently you have to respond to it and how many resources must be put toward its resolution. Tracking these potential problems early and often can lead to intercepting them before your email strategy is significantly weakened and send domains are entirely blacklisted; update your subject line now and avoid getting blocked later.
Getting to the root of deliverability issues will ensure your email strategy is sustainable for years to come. As right-party contact rates continue to fall and digital channels take priority over phone calls, starting to track your email performance now and understanding how to measure your digital strategy’s success will get your team ahead of the collections curve.
Does this all seem a bit daunting? We get it. Talk to our team today to see how we can help perfect your digital collections strategy.
Traditional call and collect strategies are becoming increasingly difficult to maintain. High agent turnover rates, plummeting right party contact rates, and ever-evolving legislation are driving companies to abandon long-standing practices and seek new solutions.
The two driving options for bringing collections strategies into the digital world are integrating digital collections software into an existing plan or partnering with a 3rd-party, digital debt collection agency. What are the key differences and which one will work for you? Let’s take a look at the pros and cons of each to help your team make a decision.
Debt Collection Software
Collections software can help existing teams build new, digital infrastructure. They cover a wide range of services including:
Customizable self-service portals
A/B testing for communication
Engagement reporting
SMS and email automation
Chatbots
Pay by text tools
These tools offer the ability to engage consumers based on their preferences for time and digital channels. They also bridge the gap between traditional collections methods and consumers that prefer emails and online portals over phone calls.
Compliance support
Software as a service (SaaS) companies in the collections space also boast built-in compliance adherence and aim to decrease the risk of agent-driven call centers.
Cons
Debt collections software solutions can offer incredibly extensive performance evaluation and automation tools, but the volume of tools available can easily become overwhelming for teams new to a digital experience. This can lead to underuse and turn a powerful tool into a wasted resource.
There is also a struggle at the industry level to help transition collections into a digital space. Call and collect strategies continue to be the norm for collections, and the voices seeking to shift the industry in a new direction are met with the Innovator’s Dilemma: “the very decision-making and resource allocation processes that are key to the success of established companies are the very processes that reject disruptive technologies…”
This caution is multiplied by the fact that these software platforms may not be all-in-one answers to a collection team’s problems. The process of integrating a single tool can be costly (in terms of both money and resources), and suddenly needing to integrate another one because the first solution did not offer a specific SMS-based tool, can mean a team starts to look more like they’re putting together technology tech stacks than a collection strategy.
Lastly, traditional call and collect teams that do integrate new technologies may rewire them to drive inbound phone calls rather than focusing on the possible growth of primarily digital approaches.
Digital debt collection agencies
Full-service digital debt collection agencies offer many of the same benefits provided by SaaS platforms, but they also provide the expanded assistance of an expert team and end-to-end service. Software companies provide account support and insight into product performance, but digital-first agencies not only have full teams and systems dedicated to product optimization, they also have agents that are trained to work in tandem with the digital tools.
Fully integrated teams also mean that agencies can offer simple, accelerated onboarding. In contrast, software platforms vary in how easily they can be integrated into an existing strategy, but successfully maximizing their performance still requires committed internal resources.
Third-party team support
Digital debt collection agencies support their efforts with dedicated teams:
Product development
Product teams continually develop new strategies for improved digital performance including optimization of onboarding, enabling new digital tools, and continually improving the consumer user experience.
Deliverability experts
Email deliverability teams optimize contact rates across digital channels. Deliverability metrics such as open rates and click rates become essential for evaluating the success of digital campaigns when compared to traditional call-to-collect solutions.
Building a scalable email infrastructure is incredibly challenging. Companies cannot simply start sending hundreds or thousands of emails overnight. Check out this article on how to build scalable email infrastructure.
Legal teams
Dedicated agencies require licensing and must adhere to the same regulations and laws that traditional debt collectors do. This means that digital-first agencies rely on in-house legal support and compliance to keep them up to date with evolving industry legislation.
Account executives/success specialists
Account executives serve as liaisons between the creditor and the digital agency in a similar way they would for a SaaS platform.
Cons
Digital-first debt collection agencies are not the norm. The biggest challenge to working with a digital agency is trying to understand a completely new approach to debt collection. When traditional call center metrics are no longer useful and your agency partner is ready to discuss open, click, and deliverability rates, there’s a hurdle that must be overcome to viewing collections through a new lens.
The industry is gradually realizing the effectiveness of digital debt collection agencies, but their naturalization will only come after existing agencies recognize the impact of using debt collection software and encountering the challenges that come with it first-hand.
Whether your team integrates a powerful new software platform to support your internal collections efforts or brings on a third-party digital-first partner, digital debt collection is rapidly changing the collections landscape and redefining how collectors interact with consumers.
Ready to learn more about what it means to partner with a digital-first agency? We’re happy to help. Schedule some time with our team to show you what more an agency can offer!
Without the ability to successfully deliver your collection emails to a consumer’s inbox, email cannot be a successful collection method for your agency. Email deliverability is the measure of the ability to successfully deliver an email to a user’s inbox. It is perhaps the most relevant KPI in an email-first digital collection strategy. Several factors can influence whether or not your emails even reach people including spam filters, sending times and volume, and even the content of the message itself.
A high deliverability rate then means that you are creating the right content, sharing it at the right time, and engaging your consumers. By measuring engagement through clicks, you can combine these statistics with an online payment portal to create an easily-tracked customer journey to payment without ever picking up the phone.
Pivoting to tracking deliverability rates, clicks, online payment totals, and payment plans created creates a full digital ecosystem of KPIs with better engagement than traditional call-to-collect models. Here are a few tips for making email an effective part of your collections strategy.
Borrow email metrics from marketing experts
Our own email deliverability experts have years of experience working in the digital marketing space. KPIs like open rates, click-through rates, and conversion rates aren’t just for marketing teams working on generating leads, they can offer insight into the effectiveness of your collections efforts and help you understand whether or not you’re actually reaching your consumers.
Tracking deliverability rates, clicks, online payment totals, and payment plans created creates a full digital ecosystem of KPIs with better engagement than traditional call-to-collect models. This is a lot of data to keep track of, and digital debt collection tools can provide some assistance in tracking digital and other tracking performance data.
Emails also don’t depend on urgency in the same way that phone calls do. Customers appreciate the convenience of managing their finances on their own time (25% of our customers access their accounts outside of the call hours designated of 8am-9pm by the TCPA). Analyzing open rates for different send times provides a deeper understanding of when your consumers like to be reached.
Email marketing metrics not only accomplish the same goals as more traditional call-based KPIs, but you also have an even clearer vision of your collections performance.
Authenticate and build domain reputation
Email authentication allows ISPs (Yahoo, Gmail, AOL, etc.) to properly identify an email’s sender. Any time an email is sent to and reaches a consumer, you are representing your company’s brand and reputation with that email. The actual process of email authentication requires the implementation of several authentication standards:
Sender Policy Framework (SPF)
This allows the owner of a domain to determine which servers their emails are sent from.
DomainKeys Identified Mail (DKIM)
DKIM is an encryption system that allows the email sender to claim responsibility for a message. That encrypted information can then be verified by the ISP.
This standard (and policy-making organization) further expands on these and adds linkage to the author (“From:”) domain name to improve and monitor the protection of the domain from fraudulent email. The DMARC organization continues to update policies related to domain security.
Brand Indicators for Message Identification (BIMI)
BIMI helps users to identify brands based on images included alongside their emails. Consider them an email preview profile picture to help users immediately recognize the email’s sender.*
*In order to integrate BIMI, you must have the other three standards mentioned here established first.
Interested in learning more about these standards? The Validity blog has a great series on SPF, DKIM, and DMARC for you to read here!
An authenticated domain helps to boost your domain reputation. If your send domain (the part of an email address after the @ sign) has a poor reputation, it is more likely to be relegated to a user’s spam inbox. Taking the proper steps to build authentication standards can secure your reputation against a massive hurdle that you’ll encounter otherwise.
Validate and increase RPC rates
Email validation is the process of ensuring that the emails you are sending to are valid and deliverable. Where authentication focuses on establishing your own email domains, validation verifies whether or not the consumer email addresses that you have on file are valid emails.
Sending an email to a non-existent email address will cause the email to bounce; you will receive a notice that the email could not successfully be delivered. A high bounce rate from emailing too many invalid users will be perceived by ISPs as poor list management—a common practice of batch email scammers—and your sender reputation will be damaged and your deliverability will drop.
In the digital collections world, sending to valid email addresses is also directly related to your right party contact rate. By validating your email lists, you can quickly identify which of your consumers have valid contact information in your system. With this information on hand, you can directly reach out to those that do, build your domain reputation, and learn which of your customers you’ll have to reach out to for updated information.
Not every traditional debt collection agency is using email extensively, but it is an invaluable tool in the age of digital communication. Understanding the technical aspects of email deliverability and the challenges that come with properly scaling your digital communications will help you overcome contact hurdles that are more challenging now than ever before.
Building scalable technology requires constant evaluation and improvement. Experimenting is defined by trying new things and creating effective changes that help teams to make informed decisions around product development. Trying new things creates momentum, and organizations that are driven by experimentation turn that momentum into growth.
Machine learning and artificial intelligence support large-scale, concurrent experimentation that helps these technologies to improve upon themselves. With the right tools in place, you can test a variety of scenarios simultaneously.
For example, we use our systems to track changes in the collection process and better understand how our digital collections efforts can be improved. Since digital-first channels offer thorough tracking and analysis, including real-time tracking on our website, we can learn in short cycles and continuously improve our product.
This kind of frequent experimentation helps to avoid making product development decisions based on untested hunches. Instead, you can test your instincts, measure them carefully, and invest energy where it matters.
Machine learning drives the experimentation engine
Aggregating historical data and processing it using machine learning algorithms and artificial intelligence helps you to understand their effectiveness. Regardless of how intelligent your learning algorithms may be, waiting to test and expand your knowledge base before marching blindly ahead can make or break the success of your product.
To launch an experiment, we follow these steps:
Start with a hypothesis that you want to test
Assign a dedicated team to manage the experiment
Monitor the performance of the test as it is guided by machine learning
Iterate
B2B companies can benefit from partnering directly with clients to customize experiments for their unique product lines in order to make experimentation-based optimization an ongoing process for both new and existing business. Keep in mind that the goal of product optimization is not always jumping to the finish line.
Understanding how your product works ultimately offers you and your customers more value, but it’s easy to become distracted by positive outcomes. Effective, scalable products require intentional design; if you’ve accomplished a goal, but the path there was accidental, taking a few steps back to review that progress and test it can help you to get a clearer picture and grow the way you want.
Below are two sample experiments we conducted to optimize our machine learning algorithms.
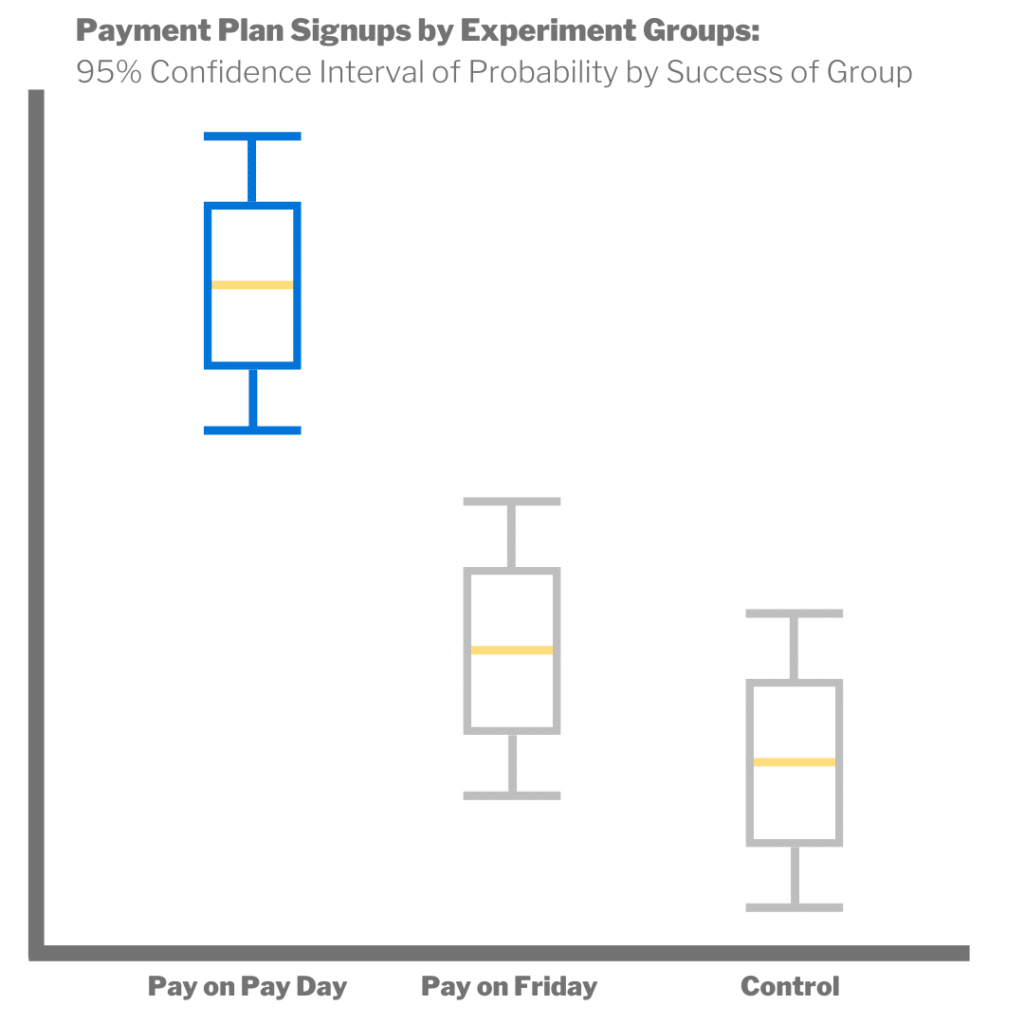
Experiment #1: Aligning Payments to Income
Issue
The number one reason payment plans fail is consumers don’t have enough money on their card or in their bank account.
Hypothesis
If you align debt payments with paydays, consumers are more likely to have funds available, and payment plan breakage is reduced.
Experiment
We tested three scenarios: a control, one where we defaulted to payments on Fridays, and one where consumers used a date-picker to align with their payments with their payday. After testing and analysis, we determined that the date-picker approach was the most effective as measured by decreased payment plan breakage without negatively impacting conversion rates.
By understanding which payment plan system was the most effective, we were able to provide our AI content that offered these plans as options to more consumers and integrate the knowledge back into our systems and track those improvements at a larger scale!
Experiment #2: Longer payment plans can re-engage consumers
Issue
Customers dropped off their payment plans and stopped replying to our communications.
Hypothesis
Customers can be enticed to sign up for a new plan if offered longer payment plan terms.
Experiment
We identified a select group of non-responsive consumers that had broken from their payment plans and sent them additional text messages and emails. These additional messages offered longer payment plan terms than the plans they broke off from.
Ultimately, we found that offering longer payment plans, even with reference to the consumer’s specific life situations didn’t lead to an increase in sign-ups. The offers that we sent had high open and click rates but did not convert. This indicated that we were on the right track but needed to iterate and come up with another hypothesis to test.
This experiment was especially important because it illustrates that not every hypothesis is proven to be correct, and that’s okay! Experimentation processes take time, and the more information you can gather, the better your results will be in the future.
We’re able to simultaneously update our product and continue experimenting, thanks to algorithms called contextual or multi-armed bandits. Here’s what you need to know about these algorithms and how they help!
Building the newest, most innovative products feels exciting, but building without carefully determined direction can be reckless and dangerous. By regularly evaluating the effectiveness of machine learning algorithms, you can make conscious updates that lead to scalable change, and experimentation paves the way for consistent product improvement.
Using email as a channel for consumer communication seems like a simple way to dive into the digital revolution, but internet service providers (ISPs) actively develop tools to combat spam and abuse.
You may have the best intentions, but these service providers want to help consumers feel like they are protected which means blacklisting and filtering out junk mail. Unfortunately, emails sent by the untrained email sender can veer dangerously close to junk.
This can make breaking into emailing consumers difficult, but it makes sending emails by the thousands (and millions) impossible without building email infrastructure that is sustainable and scalable. Establishing that infrastructure begins with recognizing the challenges you might face and then considering how to best confront them.
Why scaling email infrastructure is difficult
Email communication is heavily regulated by automated filters and systems in a way that more manual forms of communication aren’t. Cell service providers, for example, do not have nearly as much control over the volume or quality of calls that their customers receive.
ISPs have dedicated engineers that design algorithms to keep their users happy, engaged, and protected from malicious senders, and an inbox packed with spam mail makes for a poor user experience. These algorithms are not perfect, and when they are designed, they lean on the side of being more restrictive than less which can lead to some misunderstanding. They may accidentally filter out an email from a legitimate sender that, according to their understanding of what is deemed safe, seems suspicious.
To make matters more complicated, each ISP has unique criteria that serve as the basis of their filtering rules. An email that is flagged as spam by Google could land safely in a Yahoo Mail inbox and vice versa. These rules are also constantly changing and updating to fight back against more advanced scammers making it impossible to create a one-and-done solution to properly sending emails at a massive scale.
Here are just a few things that spam filters analyze that you’ll need to consider:
Content: What do your emails say? Do you have any suspicious attachments or links?
Design: How do your emails look?
Sending time: Did your email arrive at 4pm or 4am?
Sending volume: How many of these emails did you send out at once?
Sending frequency: How often are you trying to email people?
Consumer engagement: Is anyone actually opening/clicking your emails?
Working to get all of these answers (and more) right is essential or you might find your email domain permanently blacklisted from one or all of the ISPs that you’re sending to. So what can you do to build a scalable infrastructure and work within these restraints?
How to successfully send email at scale
As we mentioned above, there isn’t necessarily a single, perfect solution for overcoming the innumerable hurdles to large-scale emailing. It takes dedicated and focused strategy to improve your long term inbox placement rates. Here are a few tips that our team keeps in mind as we continue to grow.
Create valuable content
The first step to making sure your emails are well-received by both users and ISP filters alike is creating the right content. Well-designed UX and carefully curated text are important, but it’s equally important that you steer clear of some phrases and keywords and trigger red flags.
Having a dedicated content team gives you the flexibility to create more personalized and more human messages that have a better chance at reaching your intended audience!
Talk to experts
We know we’ve been thorough, but fully understanding the challenges of sending email at scale isn’t something we can teach you in a few hundred words. TrueAccord has a full team of email deliverability experts on staff that can provide industry specific knowledge and know the ins-and-outs of different ISPs’ requirements.
They also regularly audit our deliverability rates so that we can iterate on our processes and improve and help segment our domains and IP addresses as we grow.
Segment domains and IP addresses
Thankfully, our email experts can help explain what that last bit means. Segmenting your domains simply means building different domains that you can email consumers from. For example, some of your emails may come from emails@companyA.com and others may come from emails@help.companyA.com. The same goes for segmenting IP addresses; you may send some of your emails from your main office and others from your satellite office.
This process can help to limit the risk to your brand’s reputation with ISPs as you are less likely to take a big hit if only one of your many email addresses makes a mistake (e.g. bouncing frequently, receiving a lot of spam complaints, having many of its emails remain unopened).
This process is intricate and methodical. Creating ten new domains can’t solve deliverability problems because brand new domains also lack authority. If an ISP’s filters see that a brand new email address is sending out 100,000 emails, it’s likely that it’ll be swept to the side. Which brings us to our next point!
Take it slow
Scaling your program too quickly is heavily penalized even among senders with high engagements. Many well-established companies that want to build a large scale email strategy with their existing customer base make this mistake, and sometimes there isn’t a way to fix it. Placing strict limits on email volume growth can help ensure that ISPs don’t flag your domain.
Track your data
Set your benchmarks, track your performance, and make changes as you go. Data is the life blood of a scalable email program. As you’ve seen, there’s a lot to keep track of, and if any segments of your strategy spring a leak, the ship might sink.
By frequently and carefully monitoring performance—from open and click rates to inboxing rates to bounce rates—you can maintain a full view of your email strategy and make improvements as you build.
No one has the power to flip a switch and send millions of emails per month without risk, but if you build slowly, you can lay the foundation for a successful email strategy. If you have any questions, let us know in the comments below!
TrueAccord sends 40x more emails and has up to 70% higher inboxing rates than other collection agencies. Chat with our team today to learn more about what that means for you!
TrueAccord is a machine-learning and Al-driven 3rd-party debt collection company that is reinventing debt collection. We make debt collection empathetic and customer-focused and deliver a great user experience.
Our digital-first approach to debt collection creates a cycle of collections growth:
1. Improve the perception of the industry
2. Provide a personalized experience
3. Build brand equity and collect