The COVID-19 crisis has rapidly changed the way individuals and businesses operate around the world, and with no clear end to the pandemic in sight, it’s unclear when, or how quickly, the economy will start to recover. To better understand the effect this uncertainty has had on debt collection, we analyzed data from over 12 million consumers of major banks, issuers, eCommerce companies, and direct lenders.
In our upcoming report, Consumer Debt in the Age of COVID-19, we use this data to review consumer repayment trends, the role of stimulus checks in that process, and what debt collection companies will need to do to adapt.
Here’s what you can expect from the report:
Pre-coronavirus payment insights. In order to provide a benchmark for new or rapidly changing consumer behavior, we reviewed common pre-pandemic payment trends, like payment surges during tax season.
COVID, CARES, and consumer concerns. We tracked consumer behaviors around engagement and payments throughout the crisis—from the onset to the declaration of a national emergency, passing of the CARES Act, distribution of stimulus checks, and beyond. Consumers were clearly concerned early in the crisis—engagement with debt was down 40% year over year in mid-March—but when stimulus checks provided an infusion of cash, consumers overwhelmingly chose to use it to pay their debts.
Click through rates plummeted in March as the crisis worsened, only to reach a record high post-stimulus.
What’s next for debt collection? As the crisis continues and consumer payments are slowing, debt collectors must adapt to survive. Based on the payment and engagement trends outlined in the report, we share four key steps debt collection companies can take to best serve consumers in the “new normal.”
If you’re interested in reading the full report, fill out the form below to get notified when it goes live.
Building scalable technology requires constant evaluation and improvement. Experimenting is defined by trying new things and creating effective changes that help teams to make informed decisions around product development. Trying new things creates momentum, and organizations that are driven by experimentation turn that momentum into growth.
Machine learning and artificial intelligence support large-scale, concurrent experimentation that helps these technologies to improve upon themselves. With the right tools in place, you can test a variety of scenarios simultaneously.
For example, we use our systems to track changes in the collection process and better understand how our digital collections efforts can be improved. Since digital-first channels offer thorough tracking and analysis, including real-time tracking on our website, we can learn in short cycles and continuously improve our product.
This kind of frequent experimentation helps to avoid making product development decisions based on untested hunches. Instead, you can test your instincts, measure them carefully, and invest energy where it matters.
Machine learning drives the experimentation engine
Aggregating historical data and processing it using machine learning algorithms and artificial intelligence helps you to understand their effectiveness. Regardless of how intelligent your learning algorithms may be, waiting to test and expand your knowledge base before marching blindly ahead can make or break the success of your product.
To launch an experiment, we follow these steps:
Start with a hypothesis that you want to test
Assign a dedicated team to manage the experiment
Monitor the performance of the test as it is guided by machine learning
Iterate
B2B companies can benefit from partnering directly with clients to customize experiments for their unique product lines in order to make experimentation-based optimization an ongoing process for both new and existing business. Keep in mind that the goal of product optimization is not always jumping to the finish line.
Understanding how your product works ultimately offers you and your customers more value, but it’s easy to become distracted by positive outcomes. Effective, scalable products require intentional design; if you’ve accomplished a goal, but the path there was accidental, taking a few steps back to review that progress and test it can help you to get a clearer picture and grow the way you want.
Below are two sample experiments we conducted to optimize our machine learning algorithms.
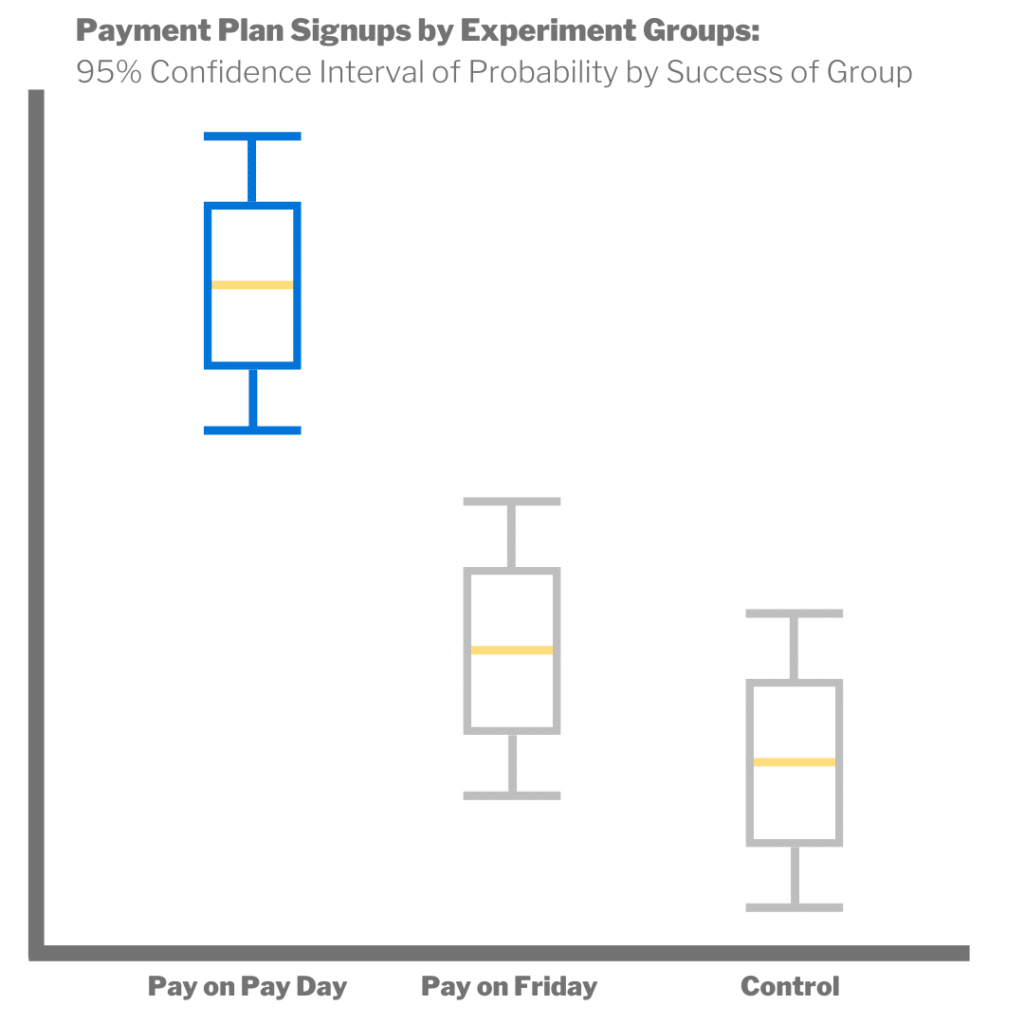
Experiment #1: Aligning Payments to Income
Issue
The number one reason payment plans fail is consumers don’t have enough money on their card or in their bank account.
Hypothesis
If you align debt payments with paydays, consumers are more likely to have funds available, and payment plan breakage is reduced.
Experiment
We tested three scenarios: a control, one where we defaulted to payments on Fridays, and one where consumers used a date-picker to align with their payments with their payday. After testing and analysis, we determined that the date-picker approach was the most effective as measured by decreased payment plan breakage without negatively impacting conversion rates.
By understanding which payment plan system was the most effective, we were able to provide our AI content that offered these plans as options to more consumers and integrate the knowledge back into our systems and track those improvements at a larger scale!
Experiment #2: Longer payment plans can re-engage consumers
Issue
Customers dropped off their payment plans and stopped replying to our communications.
Hypothesis
Customers can be enticed to sign up for a new plan if offered longer payment plan terms.
Experiment
We identified a select group of non-responsive consumers that had broken from their payment plans and sent them additional text messages and emails. These additional messages offered longer payment plan terms than the plans they broke off from.
Ultimately, we found that offering longer payment plans, even with reference to the consumer’s specific life situations didn’t lead to an increase in sign-ups. The offers that we sent had high open and click rates but did not convert. This indicated that we were on the right track but needed to iterate and come up with another hypothesis to test.
This experiment was especially important because it illustrates that not every hypothesis is proven to be correct, and that’s okay! Experimentation processes take time, and the more information you can gather, the better your results will be in the future.
We’re able to simultaneously update our product and continue experimenting, thanks to algorithms called contextual or multi-armed bandits. Here’s what you need to know about these algorithms and how they help!
Building the newest, most innovative products feels exciting, but building without carefully determined direction can be reckless and dangerous. By regularly evaluating the effectiveness of machine learning algorithms, you can make conscious updates that lead to scalable change, and experimentation paves the way for consistent product improvement.
Machine learning algorithms are playing a key role in the collections industry’s technological growth. Companies are working to integrate artificial intelligence and machine learning into their strategies in response to changing regulations and evolving consumer preferences. These processes can look dramatically different from business to business!
Some technologies are being applied to optimize traditional call and collect strategies while others are building digital-first outreach platforms. Understanding how these algorithms are working for the industry can provide insight into the future of collections.
Business intelligence and analytics
Business intelligence platforms are the foundation for the future of collections. They not only help companies understand how to best reach their existing accounts using traditional collections strategies but also integrate into other digital tools to create powerful automated systems.
These algorithms process large sets of data such as call times, call effectiveness, the value of certain accounts, collections rates, and many other variables. By analyzing this information, teams can optimize their outreach strategies by focusing on accounts that are more likely to be collected on, understand what times of day or channels work the best, and even determine what language to use in conversation with specific subsets of accounts.
Portfolio evaluation and exchange
By adding a clear scoring system to business analytics tools, teams can share their portfolios in an online marketplace with other creditors and debt buyers in order to buy, sell, and even outsource debts as needed.
While debt marketplaces are not new, real-time scoring updates and activity insights provide a dynamic, cloud-based view into a fluctuating market.
Human-like contact center agents
As companies evaluate their data and optimize their outreach, they can also integrate digital agents to interact with consumers over the phone. Artificial intelligence software can be used to create human-like voices and personalized experiences for consumers.
These platforms can operate at scale more easily than sprawling call centers but still rely on a traditional call and collect model that consumers are shying away from. As consumer preferences shift toward digital channels, more machine learning tools can help to optimize for an omnichannel experience.
Digital collections platforms
Digital collections software is able to optimize performance data and leverage it using a diverse, multi-channel communication approach. Phone calls may be included as part of a larger strategy, but these platforms are primarily built around modern consumer channels including email, SMS, push notifications, and direct drop voicemails.
Contextual bandit algorithms take channel selection to a level beyond traditional A/B testing. Even if 10% of your consumers prefer one message type to another, it’s important to understand all of your audience’s preferences.
Digital channels integrate seamlessly with decision making algorithms and can optimize communications in ways that call systems cannot. For example, digital channels like email can reach consumers outside of hours typically limited by the TCPA.
25% of TrueAccord’s consumers access their accounts outside of the 9am to 9pm when traditional agencies cannot legally reach them.
Digital debt collection agencies
Each of these implementations of machine learning help to build a more personalized, more focused, and more forward thinking debt collecting experience for both consumers and creditors. One consistent factor that does limit their effectiveness is the need to build them into existing systems or alter processes at scale.
A collection agency that bears the consumer in mind and has a machine learning-driven, digital-first strategy removes this hurdle and enables a full-service, easy to use experience for both companies and consumers. With these technologies built into a team rather than a product or service, digital debt collection agencies can provide the services outlined above alongside a dedicated infrastructure and a team of technology experts.
Choosing the right tools and support for your company’s collection efforts is more important now than ever before, and understanding the options that are available can help you to future-proof your strategy before it’s too late.
Still have questions? Our team is happy to help make sense of what a digital-first collections agency can do. Set up some time to chat!
Machine learning is a powerful tool that many companies can use to their advantage. The ability to have algorithms make decisions based on large scale sets of data enables teams to build efficient, scalable tools. Some of these algorithms require frequent monitoring and management from data scientists in order to get up to speed and continue learning. Others are able to operate and learn on their own in order to generate new information to act on!
Supervised and unsupervised machine learning algorithms both have their time and place. Let’s discuss a few examples, the difference between the two, and how they can be used together to create a powerful, AI-driven strategy for your company!
Supervised Machine Learning
Supervised learning algorithms are trained over time based on foundational data. This data will provide certain features as data points that will teach the algorithm how to generate the correct predictions. Figure 1, below, provides an example of a binary classifier and a set of data about cats and dogs that will teach the algorithm how to identify one or the other!
These models function best in situations in which there is an expected, intentionally designed output. In the example above, the expected output is that the algorithm can properly separate cats from dogs. In digital debt collection, it may be separating accounts that will be easy to collect on from ones that are more difficult.
Classification vs. Regression
The models above are both examples of a supervised learning model that is seeking classification, but supervised learning can also be used to build regression models. The key difference between the two is that in a regression model the output is a numerical value rather than categorical.
A regression-based model may use input features such as income and whether or not they have children to accurately predict a person’s age. When using a regression based model in combination with consumer data, you can even segment demographics for communication and marketing.
For full transparency we want to state that TrueAccord does not use its customer demographic data for these purposes. This is strictly an example.
With proper supervision, these models will become more accurate over time, and the data scientists building them can adjust them as business needs change. Whether you are gathering data using a regressor or a classifier, it is dependent upon the data scientists to build the most effective inputs in order to get the “correct” output.
Unsupervised Machine Learning
While supervised models require careful curation in building proper features that will lead to the “correct” output, unsupervised models can take large sets of unlabeled data and identify patterns without aid. The output variables (e.g. dog or cat) are never specified because it is now the algorithm’s job to process and sort the data based on similarities that it can identify. Using this method, you can learn things about your data that you didn’t even know!
Clustering vs. Association
Just as supervised models have primary methods for training their output data as either classification or regression models, unsupervised models can be trained using clusters or associations. Clustering algorithms gather data into groups based on like-features that exist in the data set.
If you have thousands upon thousands of customer accounts in your system, a clustering algorithm can learn using the customer data and form them into distinct (but unlabeled) groups. Once it has assigned these clusters, data scientists can review the output data and make inferences such as:
This cluster is all of the accounts that have not yet established a payment plan
This cluster is all of the users that started signing up for a payment plan but didn’t finish the process
This new data set then provides the foundation for a new outreach strategy!
Building the infrastructure to process this data is the hardest part. Learn more about how TrueAccord is laying the foundation for scalable machine learning systems!
Association algorithms are the other end of unsupervised learning algorithms. Associations take the idea of grouping random data points one step further and can make inferences based on the data available. Continuing on from our account creation example, an association-based model can identify two data points and draw conclusions based on the patterns it finds. One such pattern may be:
A person that signed up for an account the first time they opened an email is more likely to pay off their balance.
The algorithm recognizes that multiple steps in a customer’s journey creates another data point. Because association algorithms are still unsupervised, a team of scientists will be responsible for labeling the output data, but the algorithm can outline previously unnoticed patterns.
The power of teamwork
By leveraging both supervised and unsupervised machine-learning algorithms, you can make decisions based on previously unfathomable scales of data. While they cannot necessarily be used to substitute one another, they can be used to create a perpetually improving cycle. Using unsupervised models to extract meaningful information from large data sets and building new supervised models to further hone your data creates more opportunities than ever before.
TrueAccord is a machine-learning and Al-driven 3rd-party debt collection company that is reinventing debt collection. We make debt collection empathetic and customer-focused and deliver a great user experience.
Our digital-first approach to debt collection creates a cycle of collections growth:
1. Improve the perception of the industry
2. Provide a personalized experience
3. Build brand equity and collect