Building scalable technology requires constant evaluation and improvement. Experimenting is defined by trying new things and creating effective changes that help teams to make informed decisions around product development. Trying new things creates momentum, and organizations that are driven by experimentation turn that momentum into growth.
Machine learning and artificial intelligence support large-scale, concurrent experimentation that helps these technologies to improve upon themselves. With the right tools in place, you can test a variety of scenarios simultaneously.
For example, we use our systems to track changes in the collection process and better understand how our digital collections efforts can be improved. Since digital-first channels offer thorough tracking and analysis, including real-time tracking on our website, we can learn in short cycles and continuously improve our product.
This kind of frequent experimentation helps to avoid making product development decisions based on untested hunches. Instead, you can test your instincts, measure them carefully, and invest energy where it matters.
Machine learning drives the experimentation engine
Aggregating historical data and processing it using machine learning algorithms and artificial intelligence helps you to understand their effectiveness. Regardless of how intelligent your learning algorithms may be, waiting to test and expand your knowledge base before marching blindly ahead can make or break the success of your product.
To launch an experiment, we follow these steps:
- Start with a hypothesis that you want to test
- Assign a dedicated team to manage the experiment
- Monitor the performance of the test as it is guided by machine learning
- Iterate
B2B companies can benefit from partnering directly with clients to customize experiments for their unique product lines in order to make experimentation-based optimization an ongoing process for both new and existing business. Keep in mind that the goal of product optimization is not always jumping to the finish line.
Understanding how your product works ultimately offers you and your customers more value, but it’s easy to become distracted by positive outcomes. Effective, scalable products require intentional design; if you’ve accomplished a goal, but the path there was accidental, taking a few steps back to review that progress and test it can help you to get a clearer picture and grow the way you want.
Below are two sample experiments we conducted to optimize our machine learning algorithms.
Experiment #1: Aligning Payments to Income
Issue
The number one reason payment plans fail is consumers don’t have enough money on their card or in their bank account.
Hypothesis
If you align debt payments with paydays, consumers are more likely to have funds available, and payment plan breakage is reduced.
Experiment
We tested three scenarios: a control, one where we defaulted to payments on Fridays, and one where consumers used a date-picker to align with their payments with their payday. After testing and analysis, we determined that the date-picker approach was the most effective as measured by decreased payment plan breakage without negatively impacting conversion rates.
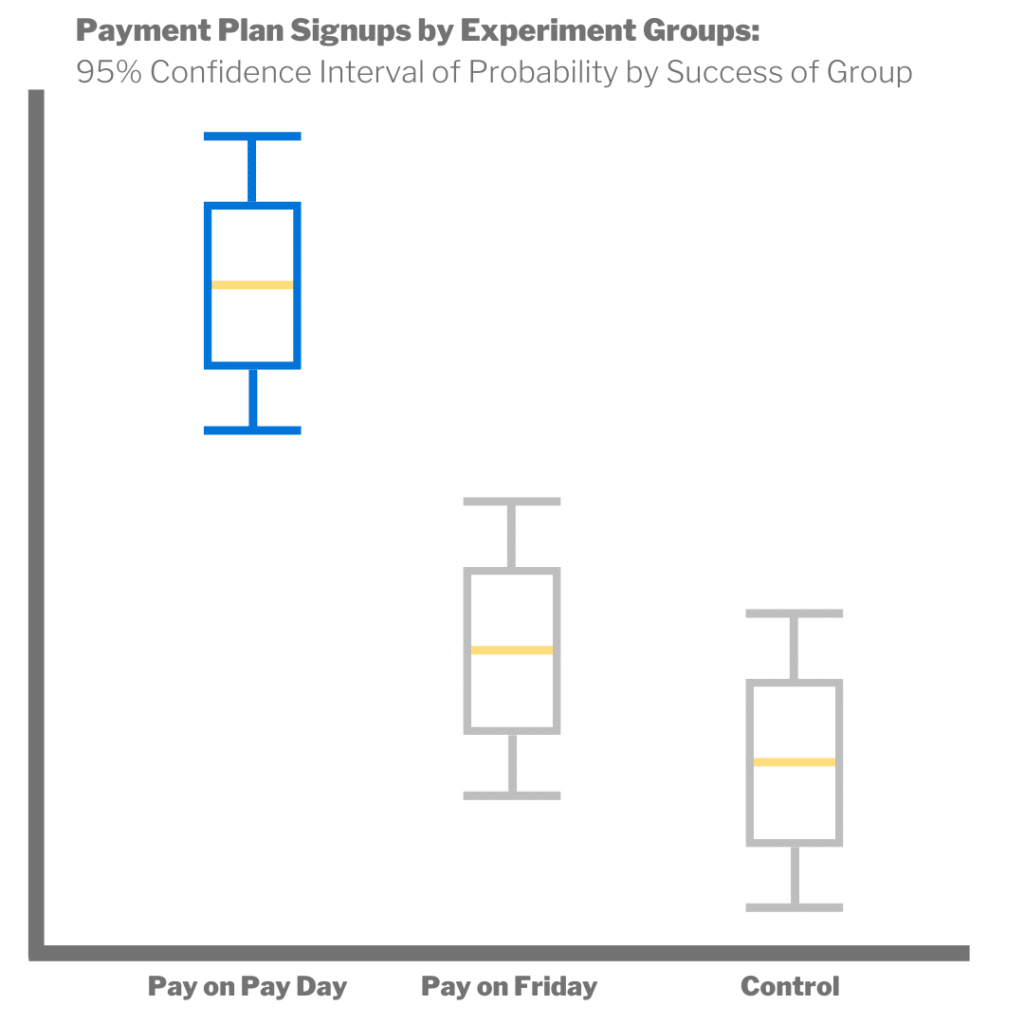
By understanding which payment plan system was the most effective, we were able to provide our AI content that offered these plans as options to more consumers and integrate the knowledge back into our systems and track those improvements at a larger scale!
Experiment #2: Longer payment plans can re-engage consumers
Issue
Customers dropped off their payment plans and stopped replying to our communications.
Hypothesis
Customers can be enticed to sign up for a new plan if offered longer payment plan terms.
Experiment
We identified a select group of non-responsive consumers that had broken from their payment plans and sent them additional text messages and emails. These additional messages offered longer payment plan terms than the plans they broke off from.
Ultimately, we found that offering longer payment plans, even with reference to the consumer’s specific life situations didn’t lead to an increase in sign-ups. The offers that we sent had high open and click rates but did not convert. This indicated that we were on the right track but needed to iterate and come up with another hypothesis to test.
This experiment was especially important because it illustrates that not every hypothesis is proven to be correct, and that’s okay! Experimentation processes take time, and the more information you can gather, the better your results will be in the future.
We’re able to simultaneously update our product and continue experimenting, thanks to algorithms called contextual or multi-armed bandits. Here’s what you need to know about these algorithms and how they help!
Building the newest, most innovative products feels exciting, but building without carefully determined direction can be reckless and dangerous. By regularly evaluating the effectiveness of machine learning algorithms, you can make conscious updates that lead to scalable change, and experimentation paves the way for consistent product improvement.